Redis Data Structure
Redis 五种数据类型
- String 字符串
- Hash 哈希
- List 列表
- Set 集合
- Zset 有序集合
Redis数据数据类型与底层数据结构对应关系

Redis键值对查找关系
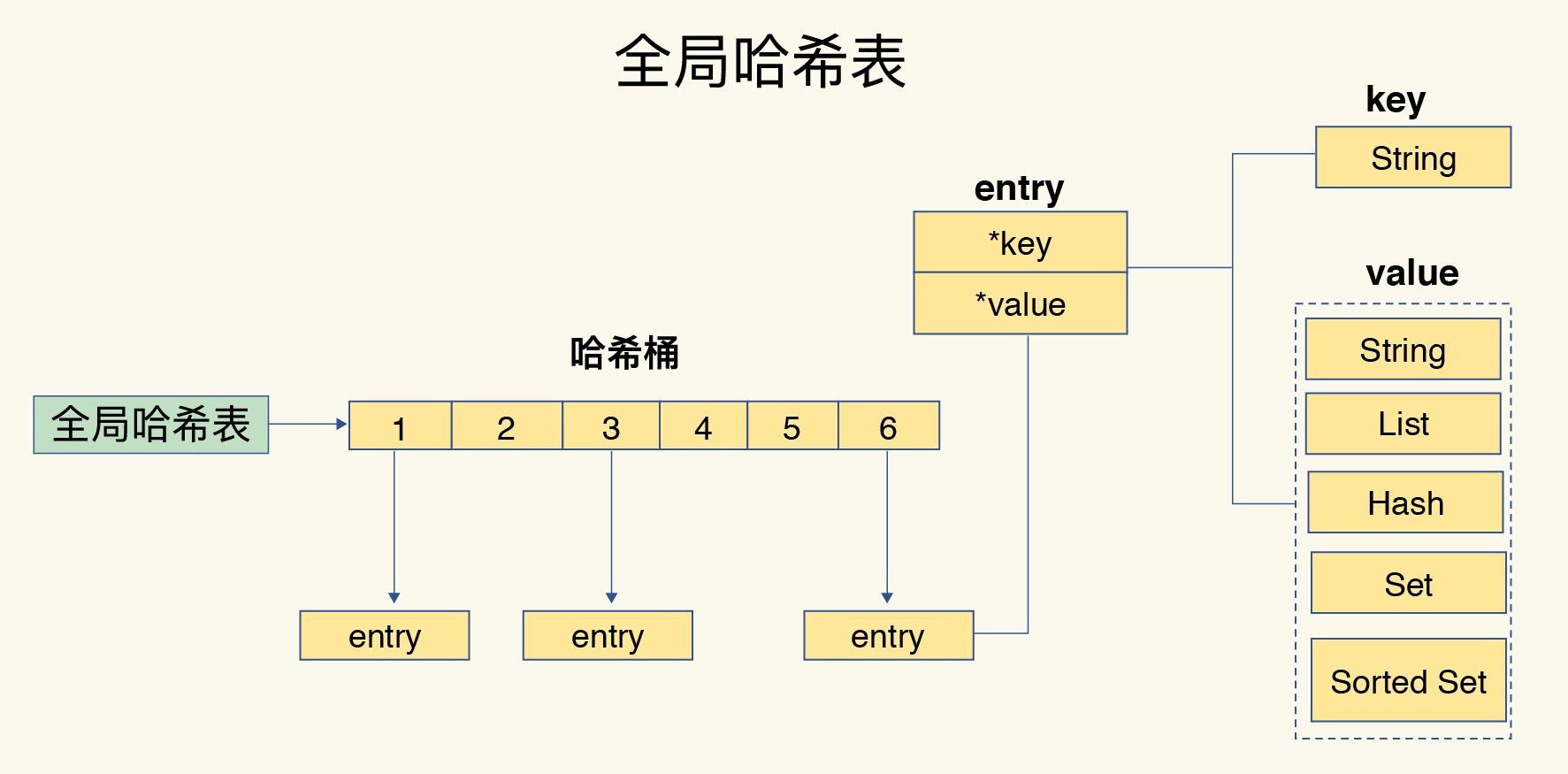
Redis为了实现从key到value到快速访问,使用哈希表的方式来存储所有键值对。
哈希表中的entry保存的并不是键值本身,而是存储的是指向具体值的指针。
使用哈希表的,可以让我们在O(1)时间复杂度下,获取指定key对应的value值。
Redis哈希冲突时rehash的过程
当我们往哈希表中写入大量的数据时,哈希冲突是不可避免的。
Redis为了解决哈希冲突,采用了链式哈希。
当发生哈希冲突时,Redis会将冲突的键值对保存在链表中。
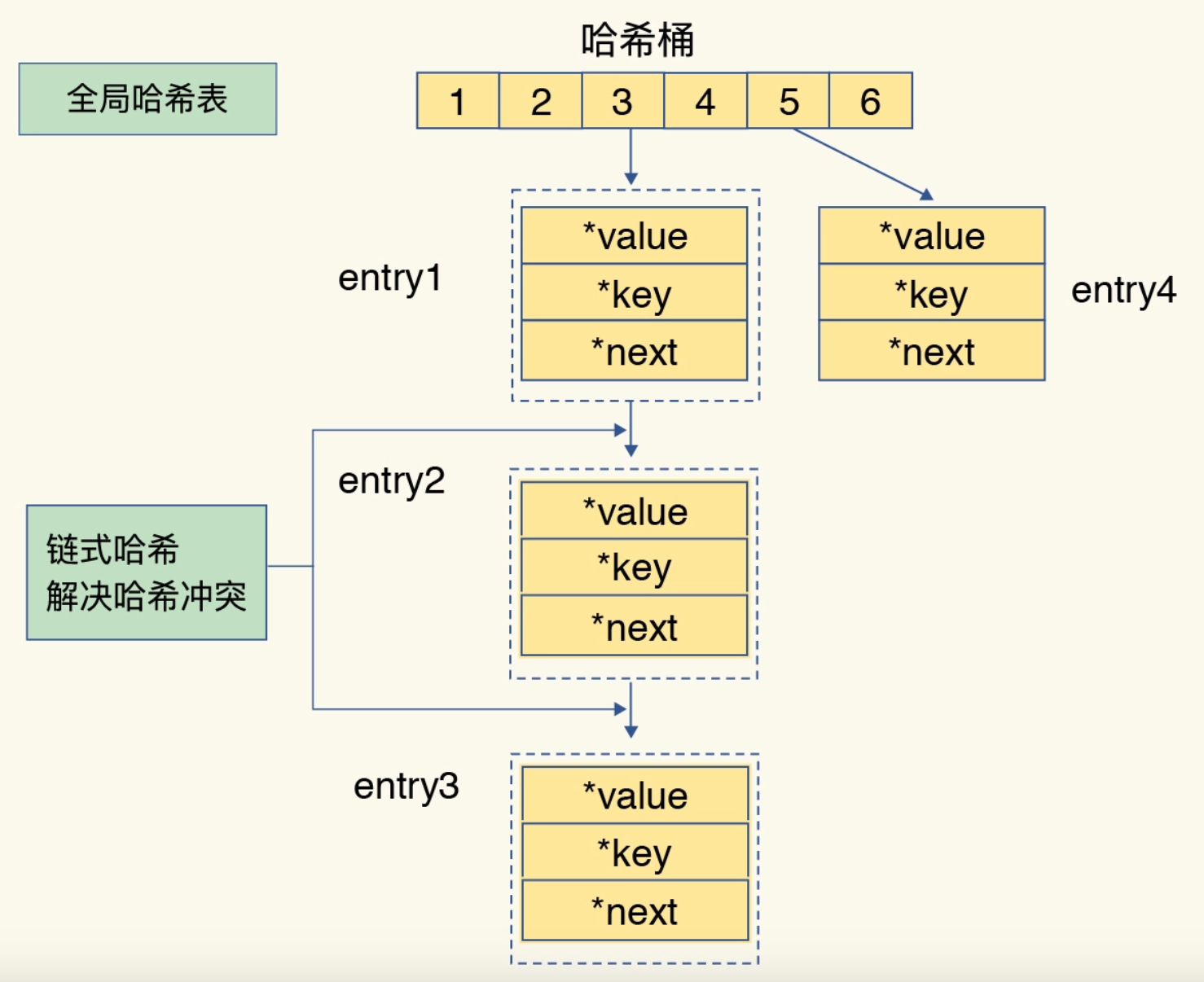
当数据量巨大时,哈希冲突链表上的节点越来越多,而其上的元素只能使用遍历的方式查找,时间复杂度为O(n)。
Redis为了解决哈希冲突导致链表过长的问题,采用了rehash。
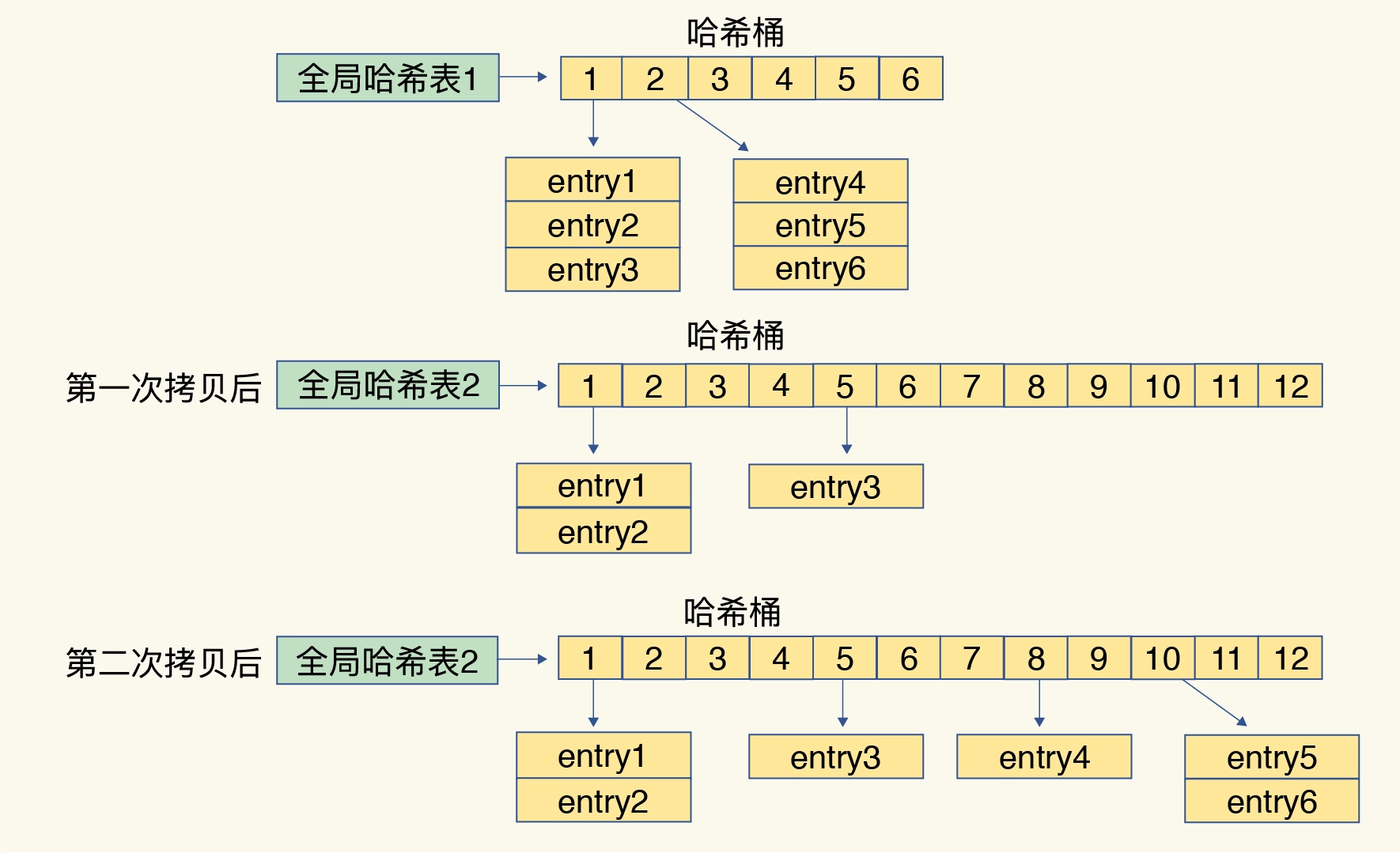
实际上Redis默认使用了两个全局哈希表,哈希表1和哈希表2。
rehash过程如下:
- 为哈希表2分配更大的空间,例如是当前哈希表大小的两倍。
- 将哈希表1中的所有键值对重新计算哈希值,并插入到哈希表2中。
- 当所有键值对都迁移完毕后,释放哈希表1,将哈希表2设置为哈希表1,然后哈希表2初始化为空表。
在这个过程中,会涉及到大量的数据拷贝,会造成Redis线程阻塞,无法完成其他服务请求。
Redis渐进式rehash
Redis为了解决rehash过程中线程阻塞的问题,采用了渐进式rehash。
渐进式rehash是指,在rehash的过程中,每次访问哈希表时,都会将哈希表1中的部分键值对迁移到哈希表2中。
这样,在rehash的过程中,哈希表1和哈希表2会同时存在,哈希表1中的键值对会逐渐迁移到哈希表2中。
Redis底层数据结构
SDS 简单动态字符串
Redis的字符串是使用SDS(Simple Dynamic String)来实现的。
SDS的结构如下:
| |
SDS与C语言中的字符串相比,有以下优点:
- 获取字符串长度的时间复杂度为O(1),而C语言中的字符串需要遍历整个字符串。
- SDS可以自动扩容,而C语言中的字符串需要手动分配内存。
- SDS可以存储二进制数据,而C语言中的字符串只能存储文本数据。
双端链表
Redis的列表是使用双端链表来实现的。
Redis中列表使用两种数据结构作为底层实现:ziplist和linkedlist。
因为双端列表占用内存比压缩列表多,所以在创建新的列表键是,列表会优先使用ziplist作为底层实现,当元素个数超过512个,或者单个元素超过64字节时,会使用linkedlist作为底层实现。
双端链表的结构如下:
| |
双端链表的特点如下:
- 节点带有prev和next指针,可以进行双向遍历。
- List保存了head和tail两个指针,因此对表头和表尾的插入和删除操作复杂度为O(1)。 这是实现高效的LPUSH、LPOP、RPUSH、RPOP操作的重要保证。
- List保存了len属性,因此计算列表长度的时间复杂度为O(1)。这是实现高效的LLEN操作的重要保证。
- List使用dup、free、match三个函数指针,可以用于复制、释放、对比节点值,从而实现多态。
双端列表迭代器
Redis为双端列表实现了一个迭代器,迭代器可以从两个方向对双端列表进行迭代。
迭代器的结构如下:
| |
- 可以沿着节点的next指针,从表头向表尾迭代。 direction为adlist.h/AL_START_HEAD
- 可以沿着节点的prev指针,从表尾向表头迭代。 direction为adlist.h/AL_START_TAIL
字典/Map/哈希表
Redis中广泛应用字典/Map,主要有以下两个用途:
- 实现数据库键空间( key space )。
- 用作Hash类型键的底层实现之一。
Hash类型使用字典和ziplist作为底层实现,因为压缩列表比字典占用内存更少,所以在创建新的Hash键时,会优先使用ziplist作为底层实现,当有需要时,才会使用字典作为底层实现。
字典实现方式有多种:
- 简单实用链表或数组实现,适用于元素个数不多的情况。
- 兼顾高效和简单性,可使用哈希表实现字典。
- 如追求更为稳定的性能特征,并能高效的实现排序操作,可使用更为复杂的平衡树实现。
字典的结构定义如下:
| |
字典所使用的哈希表实现类型的定义如下:
| |
哈希表节点( dictEntry )结构定义如下:
| |
next指针指向另一个dictEntry结构,从而形成链表,可以看出,dictht使用链地址法解决哈希冲突。
当多个不同的键拥有相同的哈希值时,哈希表使用一个链表将这些键连接起来。
字典的哈希表实现如下图所示:
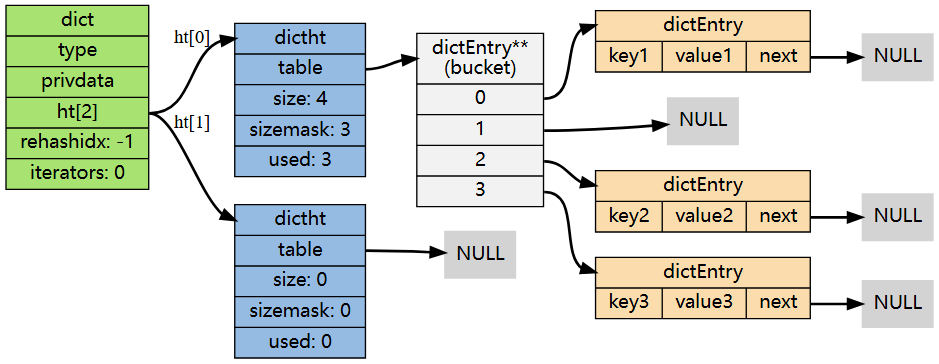
字典总结:
- Redis中数据库键空间和哈希键类型都是基于字典来实现的。
- Redis字典的底层实现为哈希表,每个字典使用两个哈希表,一般情况只使用0号哈希表,rehash的过程中才会同时使用两个哈希表。
- Redis字典的哈希表使用链地址法解决哈希冲突。
- Rehash可以用于扩展和收缩哈希表。
- 对哈希表的rehash是分多次、渐进式的进行的。
跳表
Redis的有序集合是使用跳表来实现的。
维基百科中跳表示意图:
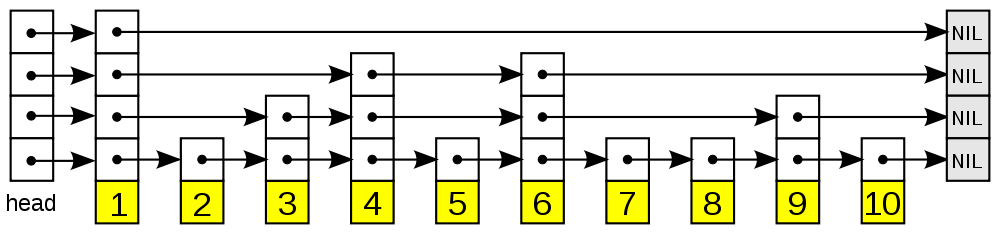
可以看出跳跃表主要由以下部分构成:
- 表头(head):负责维护跳跃表的节点指针。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于底层指针,为保证查找效率,程序总是从高层开始访问,然后缩小元素值范围,慢慢降低层次。
- 表尾:全部由NULL节点构成,表示跳跃表的尾部。
- 节点:保存着元素值,以及多个层。
跳表的结构如下:
| |
跳表按照以上结构创建的示意图:
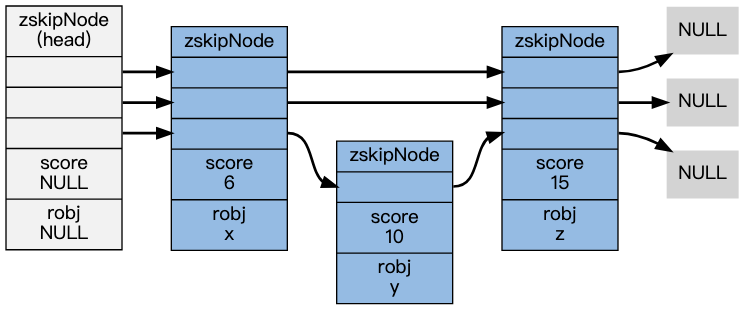
跳表的特点如下:
- 跳表是一种有序的数据结构,支持快速的查找、插入和删除操作。
- 跳表的平均时间复杂度为O(logN),最坏时间复杂度为O(N) - 逐个遍历。
- 每个节点带有高度为1层的后退指针,用于从表尾向表头遍历。
实际上跳表就是在数组的基础上,增加多级索引,从而提高查找效率。
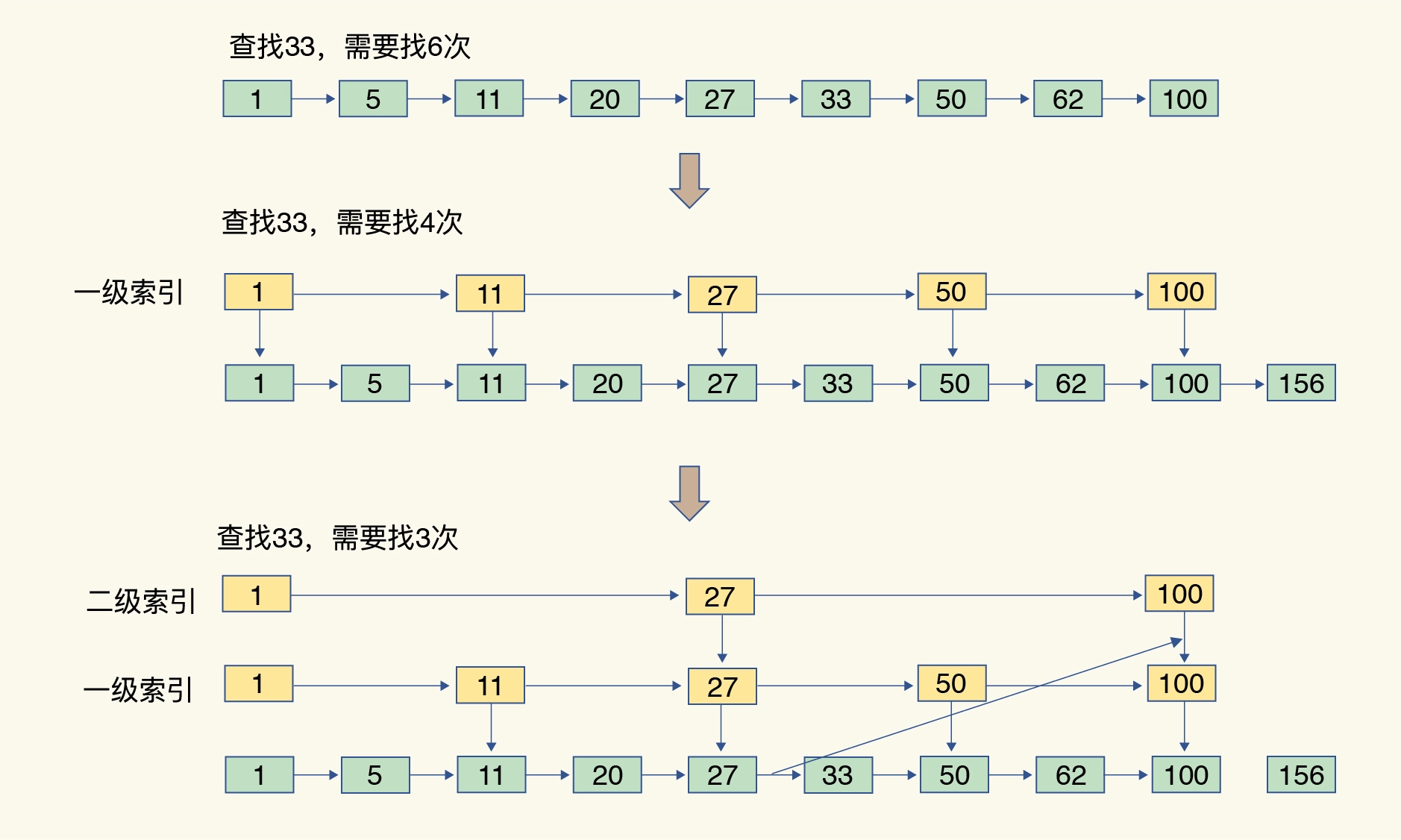
ziplist 压缩列表
Redis的列表、哈希表、有序集合在数据量较小的时候,会使用压缩列表来存储。
ziplist由一系列特殊编码的内存块构成的列表,每个节点可以保存一个长度受限的字符数组或者整数。
ziplist典型的分布结构:
| |
其中:
- zlbytes:记录整个压缩列表占用的内存字节数。在ziplist内存重新分配和计算末端时使用。
- zltail:到达ziplist尾部的偏移量,通过这个偏移量,可在不遍历整个ziplist的条件下快速定位到尾节点。
- zllen:ziplist中节点的数量。当ziplist节点数量小于UINT16_MAX时,这个值就是节点数量;当这个值是UINT16_MAX,需要遍历整个ziplist才能获取节点数量。
- entryX:压缩列表的各个节点,节点的长度由节点保存的内容决定。
- zlend:特殊值0xFF(十进制255 二进制1111 1111),用于标记压缩列表的末端。
压缩单个节点的结构如下:
| |
压缩列表的特点如下:
- 压缩列表可以节省内存空间。
- 添加和删除ziplist节点可以会引起连锁更新,因而最坏时间复杂度为O(N^2),不过出现概率不是很高,可以将添加和删除视为O(N)。