Milvus数据库
简介
什么是Milvus?
Milvus是一个高性能、高扩展性向量数据库,并且可以运行在任何规模的机器上。
Milvus是一个开源项目,使用Apache 2.0许可证。
Milvus为什么这么快?
- 硬件感知优化: 为了提高milvus在不同环境中的性能,Milvus专门优化了在许多硬件架构和平台上的性能表现,包括AVX512、SIMD、GPUs以及NVMe SSD。
- 高级搜索算法: Milvus支持广泛的in-memory和on-disk索引和搜索算法,包括IVF、HNSW、DiskANN等,所有这些算法都被深度优化过。拿FAISS和HNSWLib来说,Milvus比一般实现要更快30% - 70%。
- C++搜索引擎: 80%向量数据库的性能决定于其搜索引擎。Milvus对关键组件使用C++进行开发,因其高性能、底层优化以及高效的资源管理。最重要的是,Milvus组合使用了大量的硬件感知优化代码,从汇编层面的向量化到多线程并发和调度,尽力榨干硬件的性能潜力。
- 面向列(Column-Oriented)存储:Milvus是一个Column-Oriented的向量数据库。当执行一个查询操作时,面向列的数据库只读取特定的字段,而不需要读取一整个行数据,从而大大的减少了无效数据的访问。
Milvus架构
2022年,Milvus支持十亿尺度的向量,在2023年,Milvus支持千亿级别的向量并提高持续的稳定性支持。为300多家主要的企业提供支持,包括Paypal、Shopee、Airbnb、eBay、NVIDIA等。
Milvus的云原生和高解藕系统架构保证了整个系统可以随着数据增长而持续扩张。

Milvus本身是完全无状态的,可以很容易的借助Kubernetes或者公有云来进行伸缩。
Milvus的组件是解藕良好的,其三个主要的任务:搜索(search)、数据插入(data insertion)、索引/压缩(indexing/compaction),由于其逻辑上分离,这三个任务很容易的被设计成并行处理。这也保证了相关的查询节点、数据的以及索引节点可以独立的进行伸缩、性能优化以及成本优化。
Milvus支持的搜索类型
- ANN Search: 找到Top K个与查询向量接近的向量。
- Filtering Search: 在特定的过滤条件下执行ANN Search。
- Range Search: 在查询向量的特定范围内进行向量查找。
- Hybrid Search: 基于多个向量字段执行ANN Search。
- Keyword Search: 基于BM25进行关键字搜索。
- Reranking: 基于额外的标准或算法对搜索结果进行重排序,改善最初的ANN Search结果。
- Fetch: 基于主键取回数据。
- Query: 使用特定搜索表达式取回数据。
解释:
ANN Search: 即Approximate Nearest Neighbor Search,是一种基于向量空间的搜索算法,通过计算向量之间的距离来找到最相似的向量。Milvus支持基于向量的ANN Search,包括IVF、HNSW、PQ、OPQ等。 与精确的NN算法即Nearest Neighbor Search相比,ANN允许在寻找最近邻是稍微牺牲精度以换取更高的计算效率。这对于处理大规模数据特别重要,因为高位空间中精确搜索的计算成本非常高。
Milvus支持ANN算法包括:
- IVF(Inverted File Index): 将数据集划分为多个簇,查询时仅在相关的簇中查找,提升搜索效率。
- HNSW(Hierarchical Navigable Small World Graph):一种基于图的算法,适用于高维数据的快速相似性搜索。
- Flat: 也称为Brute-Force Search, 即遍历整个向量空间,找到与查询向量距离最近的向量。可提供小规模数据集上的精确的最近邻搜索。
- ANNOY(Approximate Nearest Neighbors Oh Yeah): 一种基于树的算法,适用于高维数据的快速相似性搜索。
- NSG(Navigating Spreading-out Graph):通过优化图的接哦股,实现高效的搜索和插入操作。
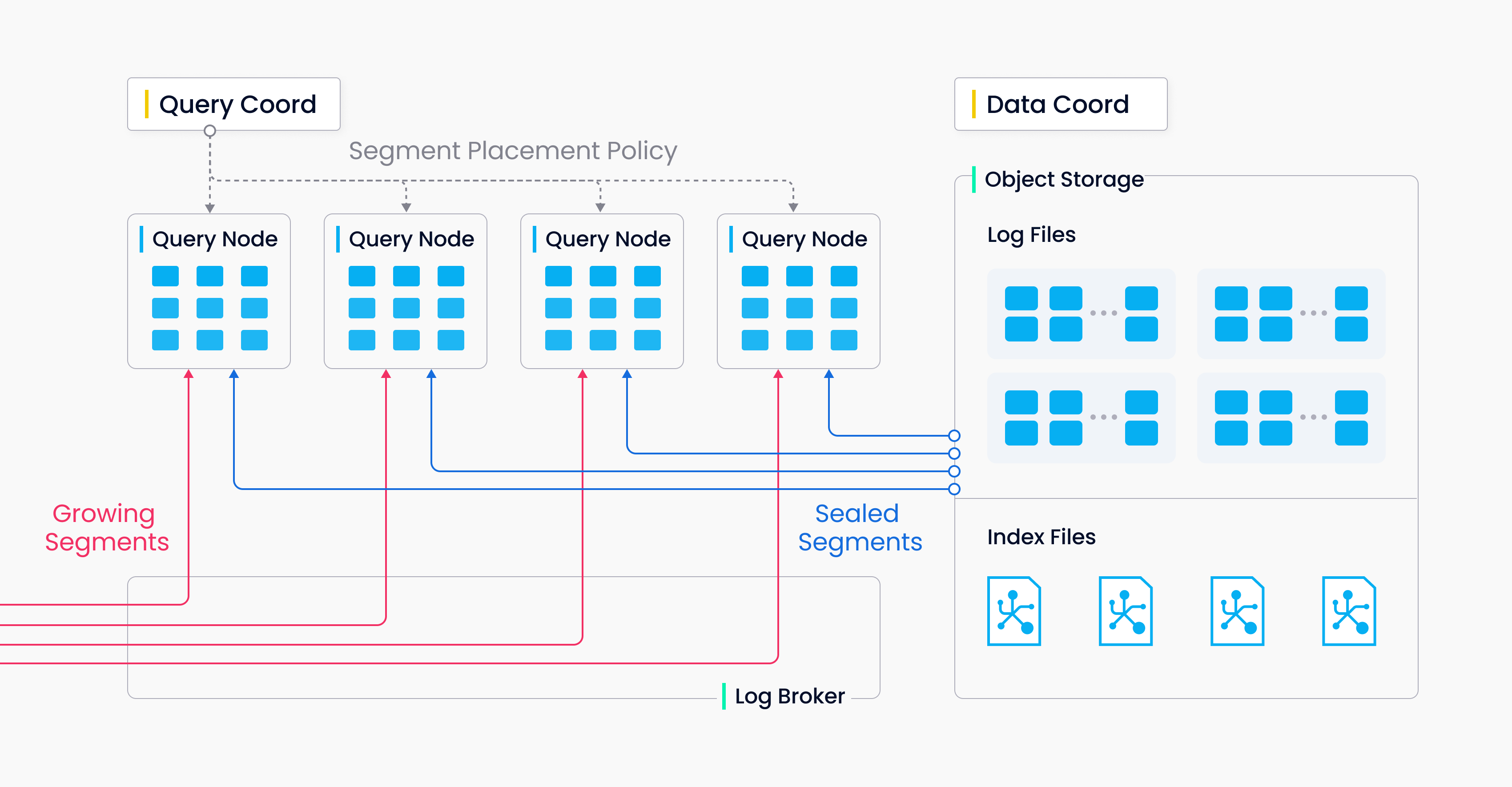
一、架构
1. 整体架构图
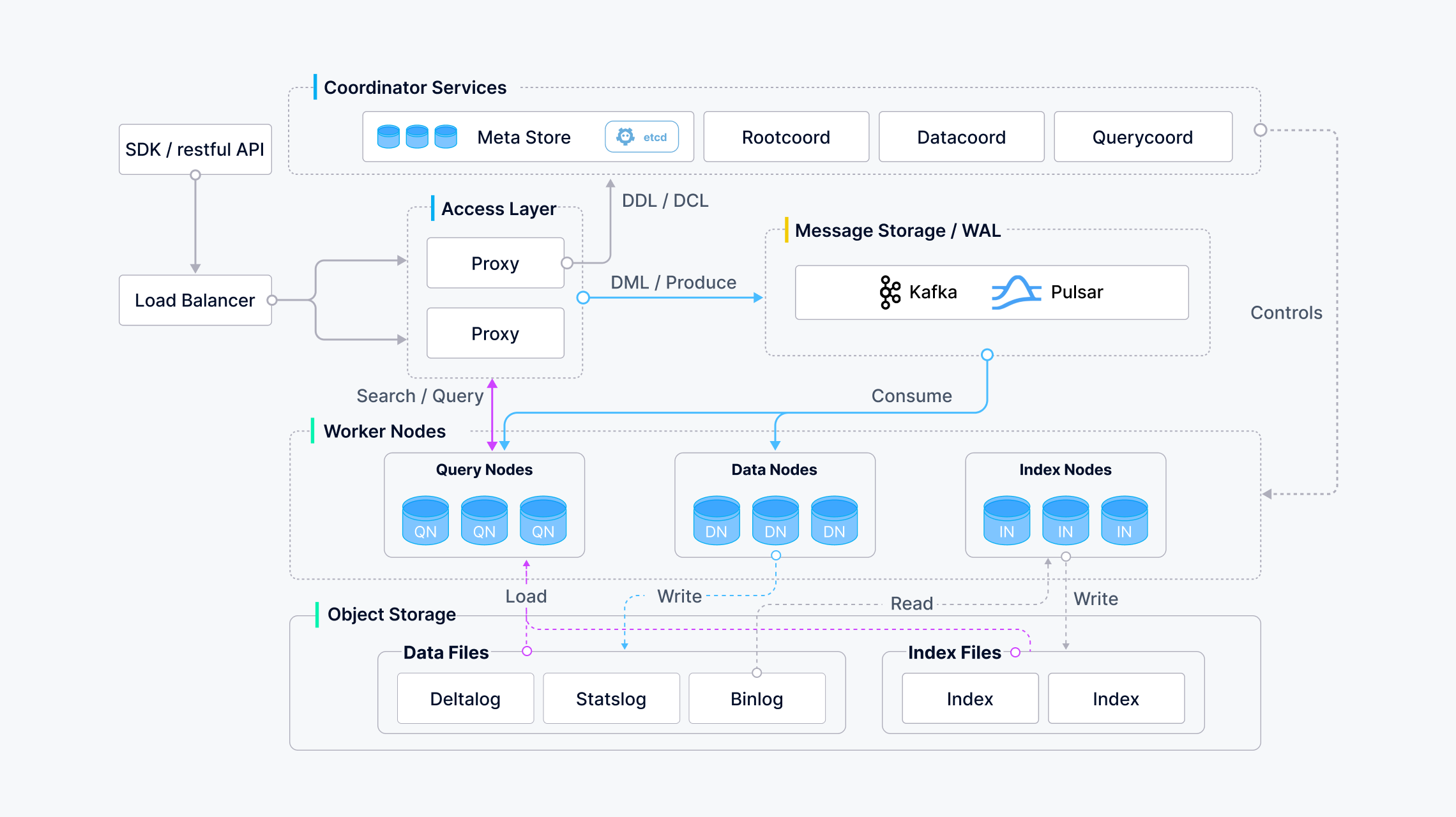
2. 主要组件
单机模式
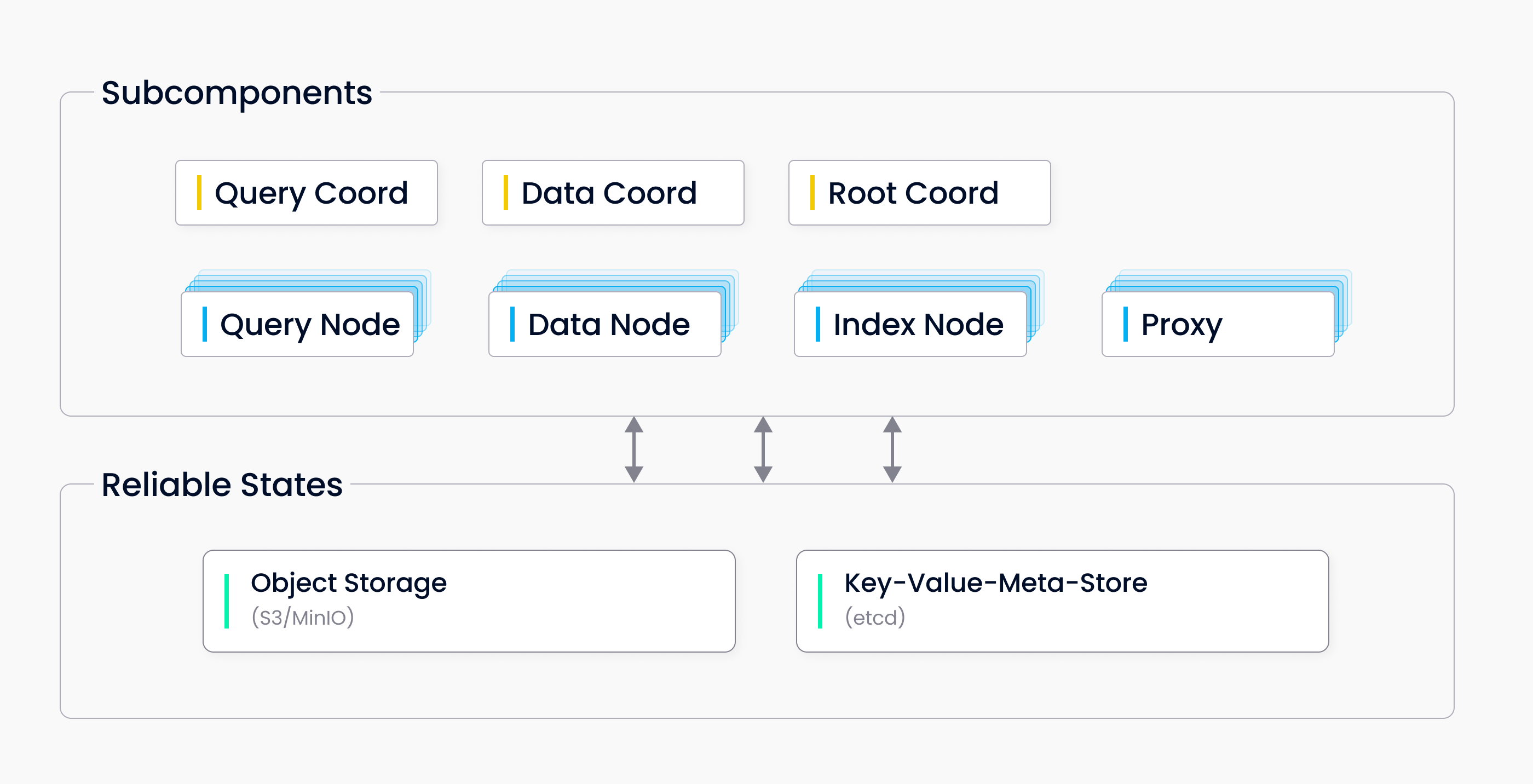
Milvus单机模式包括三个组件:
- Milvus:核心功能模块
- Mate Sotre: 元数据引擎,存储和访问Milvus内部组件包括代理、索引节点等等元数据。
- Object Storage:存储引擎,负责Milvus等数据持久化。
上图中:
Cooridinator组件:
- Root Coordinator(root coord):处理Data definition language(DDL)和Data Control language(DCL)的请求,比如创建或删除Collection、Partition、Index等。
- Query Coordinator(query coord):为查询节点提供管理拓扑关系和负载均衡的能力。
- Data Coordinator(data coord):管理数据节点和索引节点的拓扑学关系,维护元数据,触发数据刷新、压缩和索引重建以及其他的后台数据操作。
Worker Nodes组件:
工作者节点是无声的执行者,默默执行来自协作者服务(coordinator)的指令和来自代理(proxy)的Data Manipulation language(DML)命令。
工作者节点得益于其存算分离的设计,是无状态且可以很容易在k8s上的进行扩容、故障恢复。
工作者节点包括三种类型:
- Query Node: 查询节点通过订阅日志broker取回增量(incremental)的日志数据,并将其转化为增量片段(growing segments)。
- Data Node: 通过订阅日志broker取回增长式的日志数据,处理不同的请求并且打包日志数据为日志快照并将其存储在对象存储中。
- Index Node: 索引节点构建索引。索引节点不需要内存驻留,并可以通过无服务框架来实现。
Storage:
Storage是一整套系统,负责数据持久化。包括元数据存储,日志代理(log broker)和对象存储。
- Mate Storage: 元数据存储保存了一些数据结构的元数据快照,包括collection、schema和消息消费检查点。元数据的存储需要非常高的可用性和强一致性并且要支持事务,所以Milvus使用etcd来存储元数据。Milvus也使用etcd来进行服务的注册和检查。
- Object Storage: 对象存储保存了一些文件快照,包括日志文件、向量数据或常规数据的索引文件和间接查询数据文件等。Milvus目前使用MinIO作为对象存储。然而,对象存储在数据访问上有很高的延迟和性能损耗,为了提高其性能减少成本,Milvus计划基于内存或SSD的缓冲池来实现冷热数据的分离。
- Log Broker: 日志代理是一个支持重放(palyback)的发布者订阅者(pub-sub)系统。负责数据持久化传输和事件提醒。同时保证当工作者节点从系统宕机中恢复时的增量数据的完整性。Milvus集群使用Pulsar作为Log Broker。Milvus单机模式使用RocksDB作为Log Broker。此外,日志代理可以很容易的使用其他流式数据处理平台替代,比如说Kafka。
集群架构
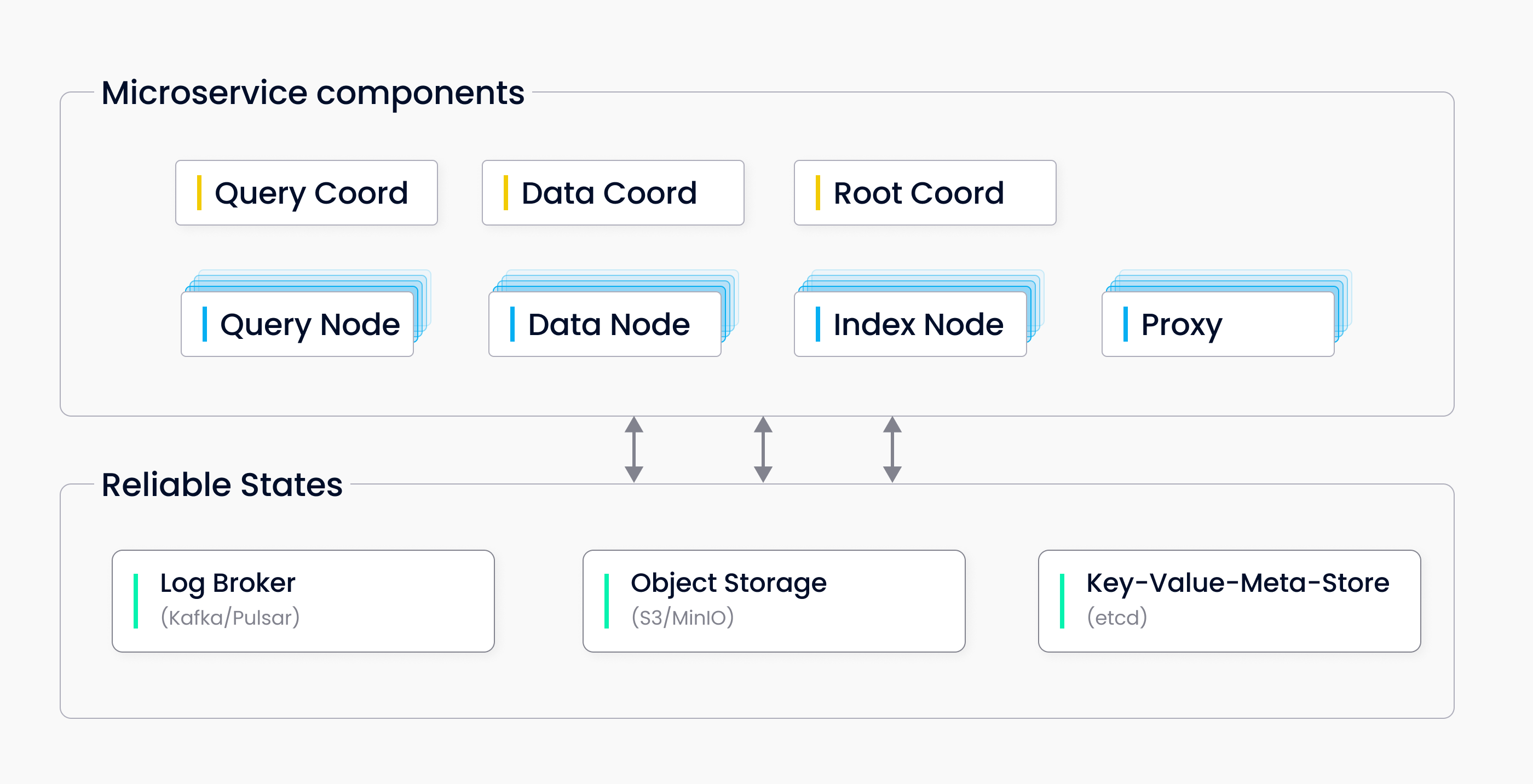
Milvus Cluster包含7个微服务组件和3个三方依赖。所有服务可以在k8s上进行单独的部署。
微服务组件包括:
- Root Coordinator
- Query Cooordinator
- Data Coordinator
- Query Node
- Data Node
- Index Node
- Proxy
三方依赖:
- Meta Store: 存储集群中各种组件的元数据,例如etcd。
- Object Storage: 负责集群中大文件的数据持久化,比如索引和二进制日志文件。使用S3/MinIO。
- Log Broker: 管理最近修改数据操作的日志,输出流式日志,并且提供日志发布者-订阅者服务。使用Pulsar。
向量引擎 Knowhere
Knowhere是Milvus的向量执行引擎,融合集中向量相似搜索库,包括Faiss、Hnswlib和Annoy。
Knowhere支持异构计算,其将控制哪些硬件(CPU或GPU)来执行向量构建和搜索请求。这也是Knowhere名字的由来,知道在哪执行操作(know where)。
Milvus架构中的Knowhere:
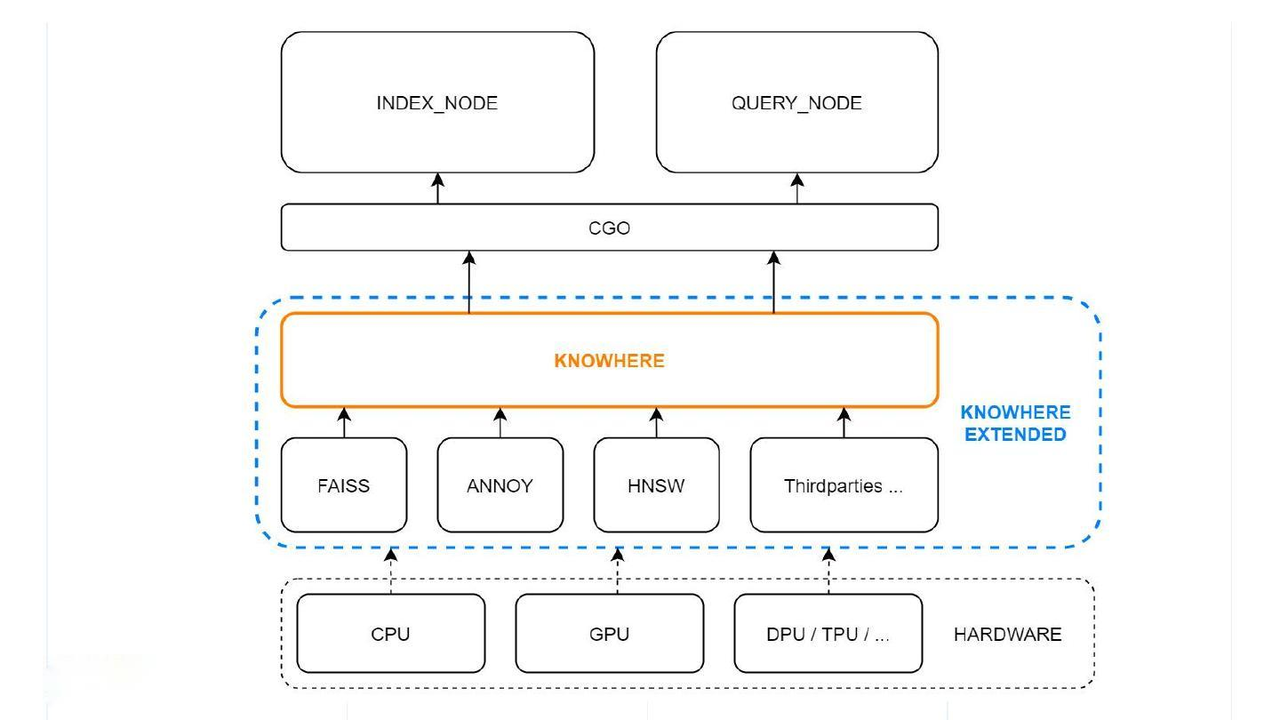
最底层是系统硬件。三方索引库在硬件层之上,然后Knowhere与索引节点和查询节点通过CGO进行交互。
二、数据处理流程
这部分包含Milvus中的数据插入、索引构建和数据查询。
1. 数据插入流程
在Milvus中可以为每个collection设置分片(shard)数量,每个分片对应一个虚拟通道(vchannel)。
如下图所示,Milvus会为每一个vchannel在log broker中分配一个物理通道(pchannel)。
所有insert/delete请求都会通过主键hash的方式路由到不同的分片。
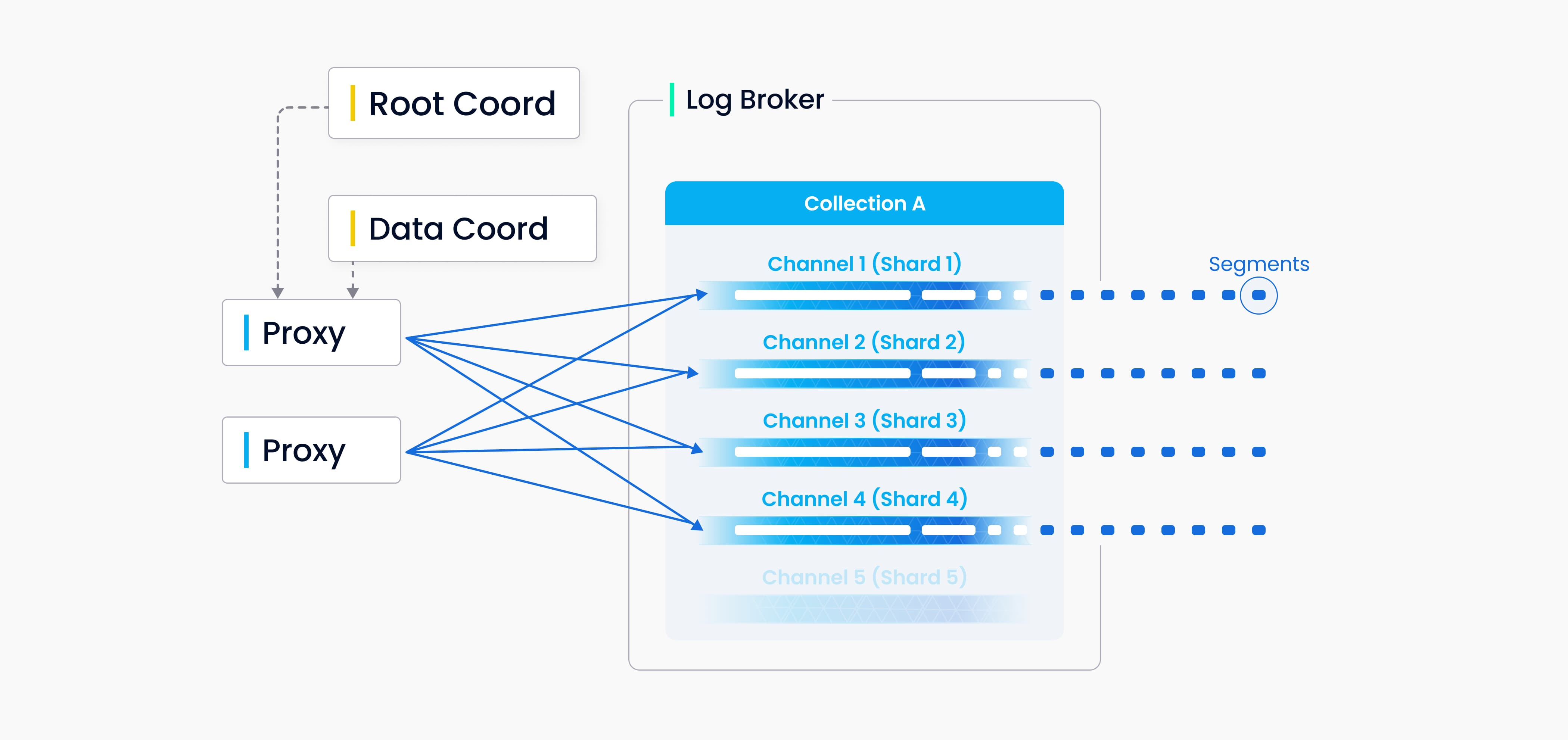
DML请求校验被移动到proxy中进行处理,因为Milvus并没有复杂的事务。
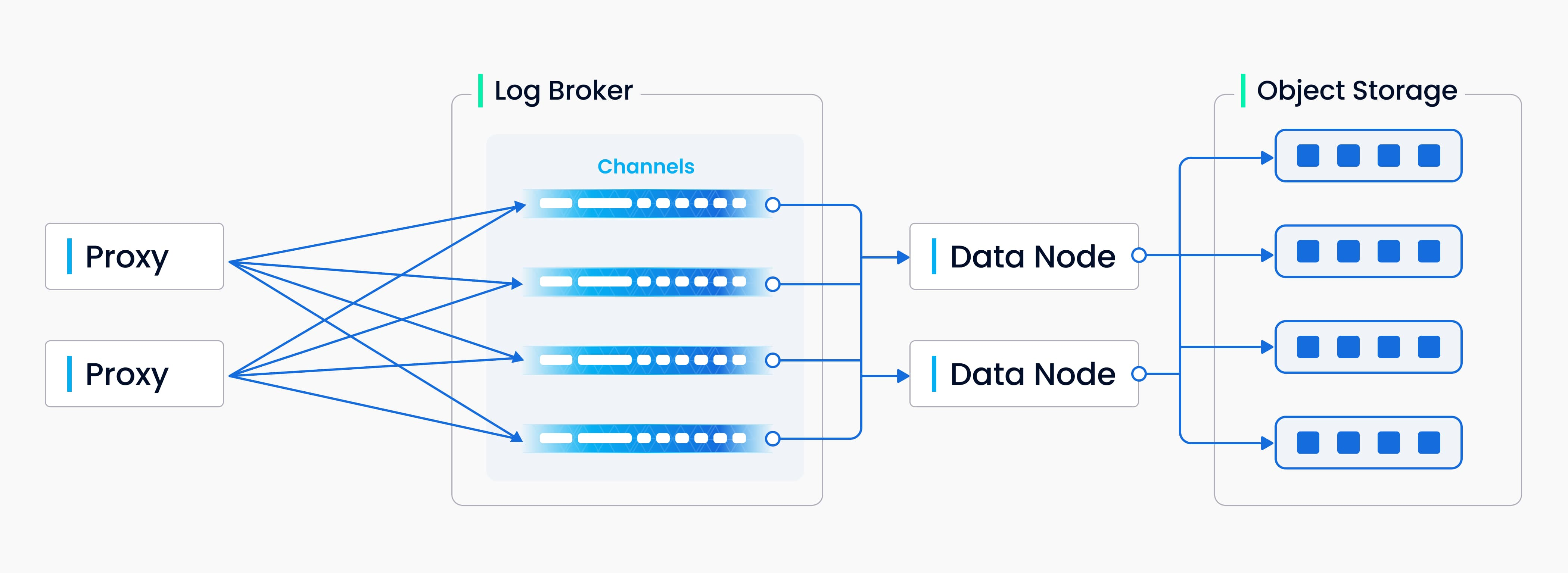
2. 索引构建流程
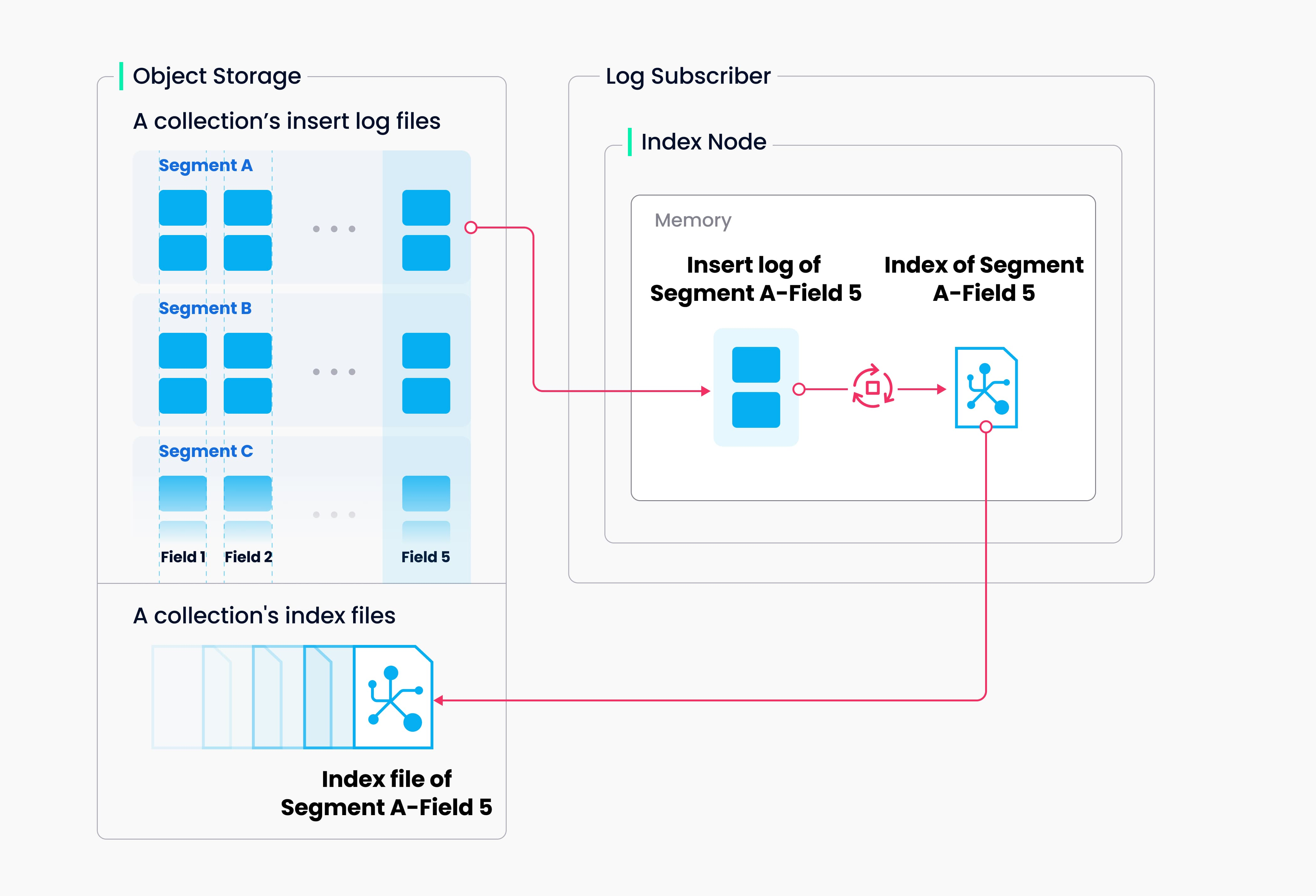
索引构建的过程在索引节点上执行。为了避免因为数据更新的导致的频繁的索引构建,一个collection在Milvus中被进一步分割成了segments,每一个segment对应一个索引文件。
Milvus支持为每个向量字段、常规字段以及主键字段构建索引。
索引构建的输入和输出都是使用对象存储进行:
索引节点从对象存储中加载一个segment的日志快照(log snapshots)到内存中,反序列化相应的数据和元数据进行索引构建,当索引构建完成时序列化索引数据并将其写入对象存储中。
3. 数据查询流程
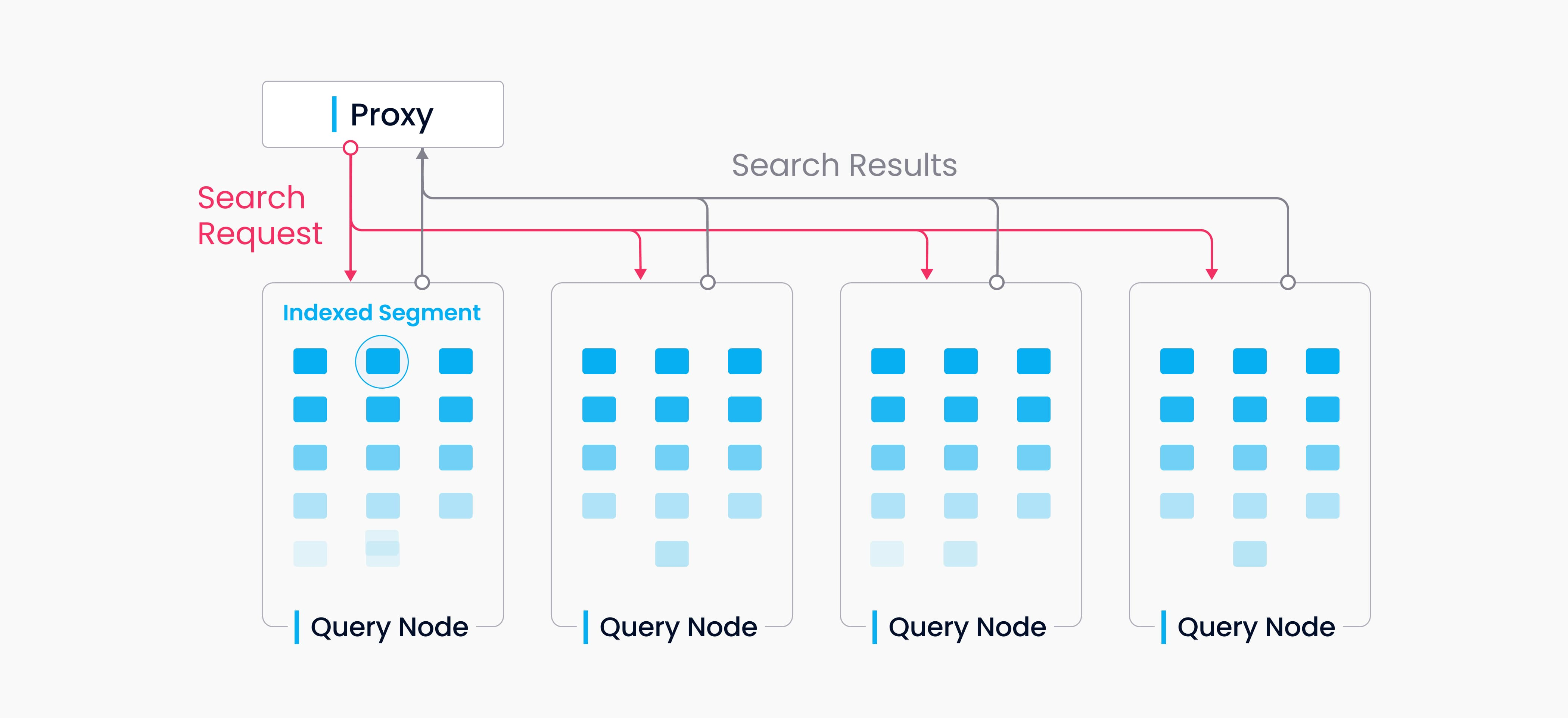
数据查询涉及到搜索与一个目标向量接近的k个向量或者模组一定距离范围内的向量的处理过程。向量会与其主键和字段同时被返回。
一个colletion会被分割成多个segments,查询节点会通过segment来加载索引。当一个搜索请求到达时,将会广播给所有查询节点以进行并发搜索。
各个查询节点在一次查询过程中相互独立。每个节点只负责两个任务:
- 遵循Query Coord的指示加载或释放segments;
- 在本地segment上实施搜索。
Proxy会负责将每个查询节点的搜索结果组合并最终返回给客户端。
4. Handoff接力流程:
Milvus中存在两种增量segments:
- 增量segment(因增量数据);
- 打包好的segment(即历史segment)。
查询节点会订阅vchannel来接收最近的更新(增量数据)作为增量segment。
当增量segment的数量到达一个预先定义的阈值时,Data Coord会将其打包,而且索引构建的流程将会被启动。
然后上图的接力(handoff)流程就被Query Coord启动了,这个过程将会把增量数据转变为历史数据。
Query Coord会将打包好的segment均匀的分配给所有的查询节点,根据其内存占用、CPU负载以及segment的数量进行分配。
三、一致性
一致性在分布式数据库中特指:
在给定的时间内,当进行数据写入或数据读取时,确保所有节点或副本拥有相同的数据视图(view of data)。
Milvus支持4中一致性级别:Strong、Bounded Staleness、Session、Eventual。
Milvus默认的一致性级别为Bounded Staleness。
1. Strong级别
是最高也是最严苛的一致性界别,其确保用户可以读取到数据的最新版本。
根据PACELC理论,在Strong级别下,请求延迟会增加。因此,推荐在功能测试的时候使用Strong级别来确保测试结果的准确性。
Strong级别也特别适合对数据一致性要求高的场景,比如金融、保险、电商等。
2. Bounded Staleness级别
Bounded Staleness意思是数据不会陈旧,但也不能保证绝对的实时性。
允许数据在一段时间内不是一致的。但是在一段时间后,数据总是逐渐变得全局一致。
Bounded Staleness级别适合那些需要把控搜索延迟并且能够接受一些零星的数据不一致的情况。
例如,在推荐系统中使用Bounded Staleness级别,一点点数据不一致的情况有时只会对整个召回率产生很小的影响,但是能够大幅的提升推荐系统的性能。
3. Session级别
Session级别能够确保在同一个session中的所有数据写入能够被立即读取到。
换句话说,当在同一个客户端上进行操作时,新插入到数据立马能够被搜索到。
Session级别适合那些对同一个session中数据一致性要求特别高的场景。
4. Eventual级别
Eventual级别不保证任何一致性,只保证最终一致性。
在Eventual级别下,数据更新后,用户可能需要等待一段时间才能看到最新的数据。
虽然如此,但是在Eventual级别下,在牺牲数据一致性的前提下,搜索延迟将会急剧下降。
因此,Eventual级别特别适合那些对数据一致性要求不高但是对搜索性能十分敏感的场景。
例如,获取亚马逊上商品的评论和评分此类场景。
5. Milvus一致性实现原理
Milvus会为每一条进入系统的记录分配一个时间戳。
Milvus同时是一个存算分离的系统,数据持久化负载由Data Node负责,最总落盘到MinIO/S3的分布式对象存储中去。
在Milvus中,Search类计算任务由Query Node负责,其会同时处理两类数据(上文提到过的):增量数据和历史数据。其中历史数据不会被更改,Search请求会看到所有历史数据。
Query Node和Data Node通过订阅机制消费用户插入的请求,这些数据构成了增量数据。由于存在网络延迟,在搜索请求到达时,Query Node可能尚持有最新的增量数据。
在Milvus中,是通过时间戳的方式来保障读取链路的一致性的.
如下图所示,在消息队列中插入数据时,Milvus还会不断的插入同步时间戳(Sync TS)。
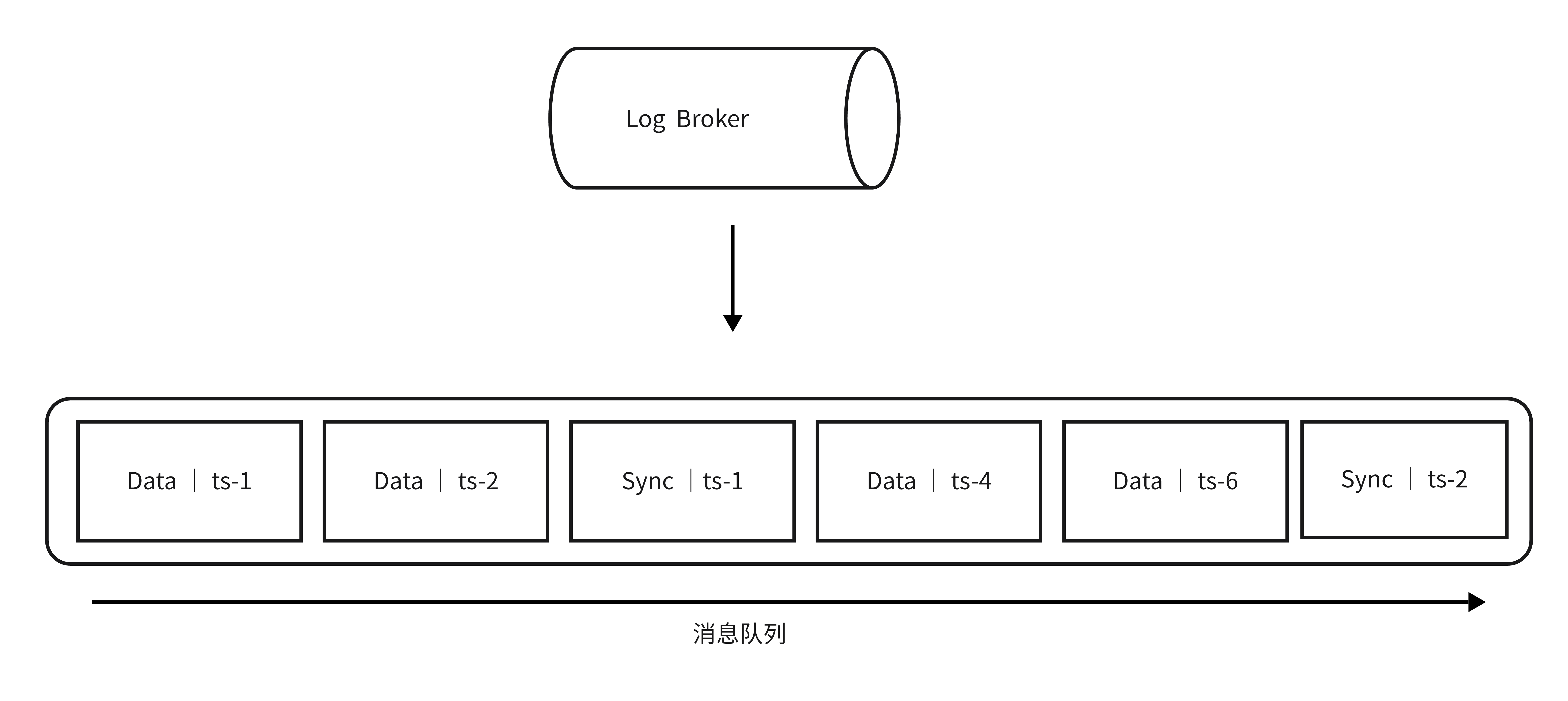
Guarantee Timestamp
当Query Node不断的从消息队列中拿到增量数据以及同步时间戳(Sync TS)时,每消费到一个Sync TS,Query Node都会将这个作为一个Service-Time。
Service-Time意味着Query Node能够看到这个时间以前的所有增量数据。
Milvus根据一致性的设置,提供了一个Guaurantee Timestamp,用户通过指定Guarantee Timestamp来确保其一致性的需求。
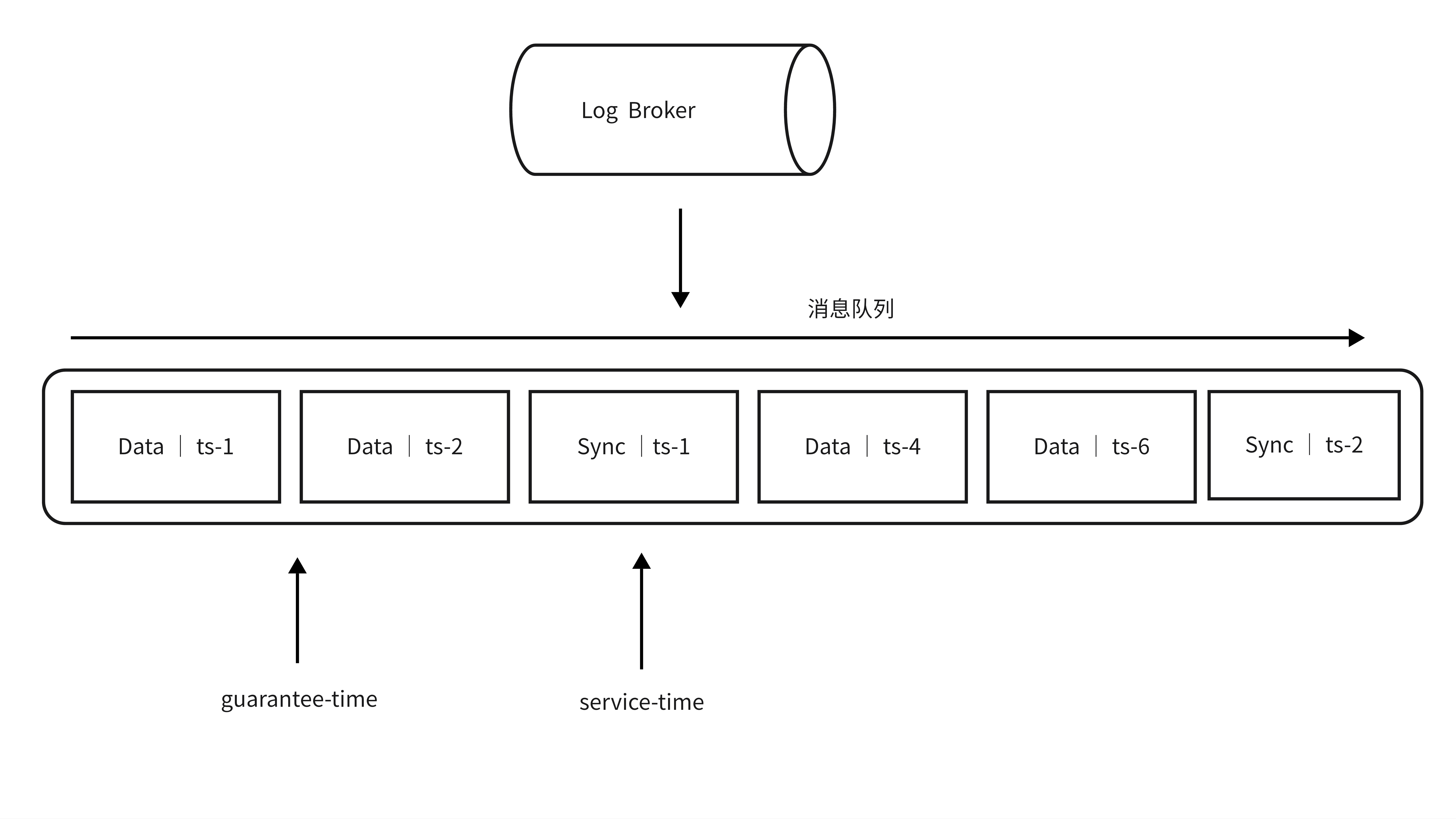
Guarantee Timestamp的位置代表了4中一致性级别:
- Strong: GuaranteeTs设置为系统最新时间戳,Query Nodes需要等待Service-Time推进到当前最新的时间戳才能执行当前搜索请求。
- Bounded Staleness:GuaranteeTs设置为一个比系统最新时间稍稍旧的时间,在可容忍的范围内立刻执行查询。
- Session:GuaranteeTs设置为当前session上次写入的时间戳,能够保障客户端立即看到自己写入的全部数据。
- Eventual:GuaranteeTs设置为一个很小的值(例如0),跳过一致性检查,立即在已有的数据上进行Search查询。
四、索引
常规字段索引
Milvus支持结合常规字段和向量字段的组合过滤搜索。为了提高常规字段的搜索效率,Milvus从2.1.0版本引入了常规字段的索引。
概览
每当执行一个向量相似度搜索时,都可以携带一个布尔表达式(boolean expression)来组织常规字段。
当Milvus收到携带布尔表达式的搜索请求时,会将其解析为一个抽象语法树(AST),并生成字段过滤计划。
Milvus然后会应用过滤计划给每一个segment来生成一个位图作为过滤结果,并使用过滤结果作为向量搜索的输入来缩小搜索范围。
在这个角度上来说,向量搜索的速度很大程度上和过滤相关字段过滤的速度有关。
常规字段索引是一种保证字段过滤速度的手段。
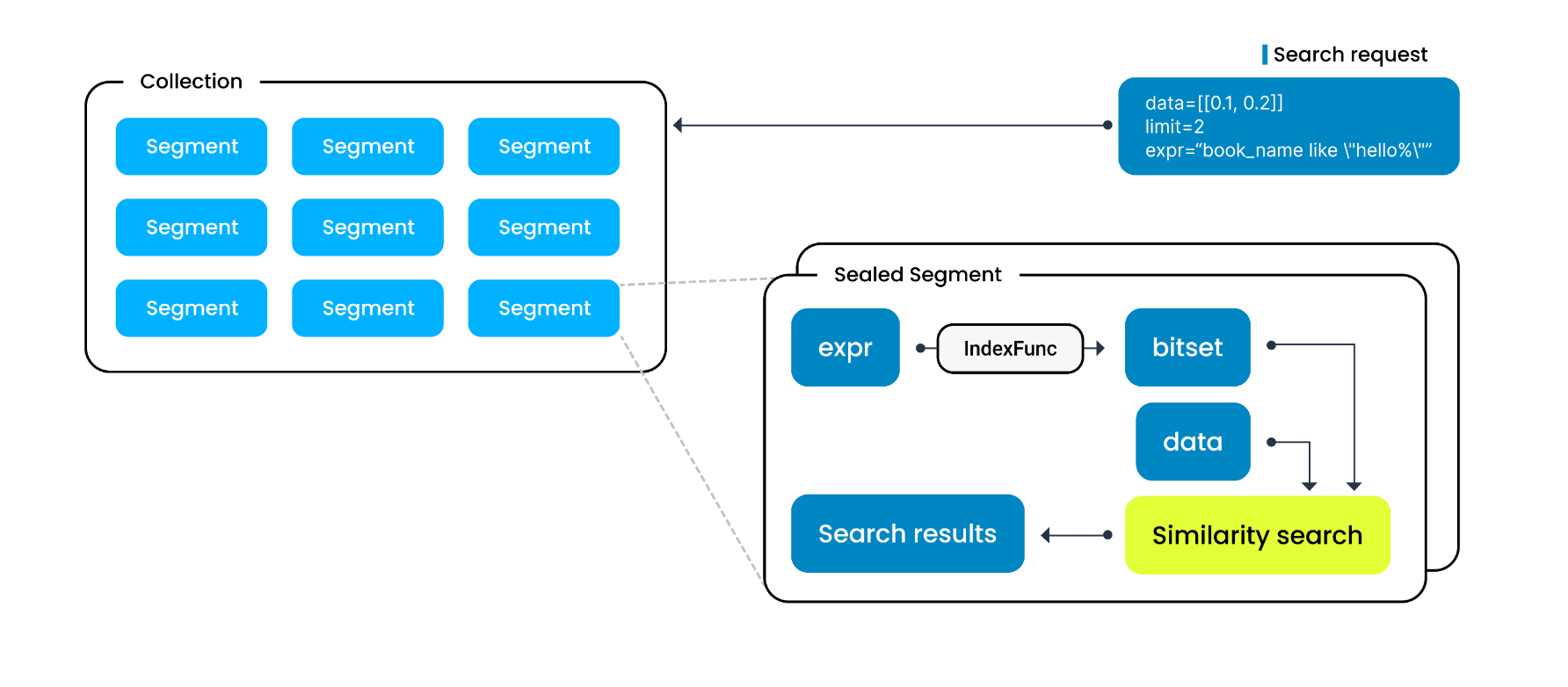
索引算法
Milvus的目标是达成一种低内存占用、高过滤效率和极少加载时间的索引算法。
在Milvus中主要使用Inverted Index(倒排索引)来来实现常规字段的索引。
以下类型字段在创建时会自动创建倒排索引以加快索引速度:
- INT8、INT16、INT32、INT64
- FLOAT
- DOUBLE
- VARCHAR
其他常规字段类型需要通过设置索引参数来手动创建索引。Milvus中索引适合单点查询、模式匹配、全文搜索、JSON搜索、Boolean搜索甚至前缀匹配。
Milvus中倒排索引利用Tantivy来实现,Tantivy是一个开源全文搜索引擎。
倒排索引中有两个主要的组件:
- 词条组成的词典(term dict)
- 倒排列表(inverted list)
词典中包含了所有根据词典表token化的词条,倒排列表中包含了每个词条对于的文档。
这种设计使得单点查询和范围查询更快更高效。
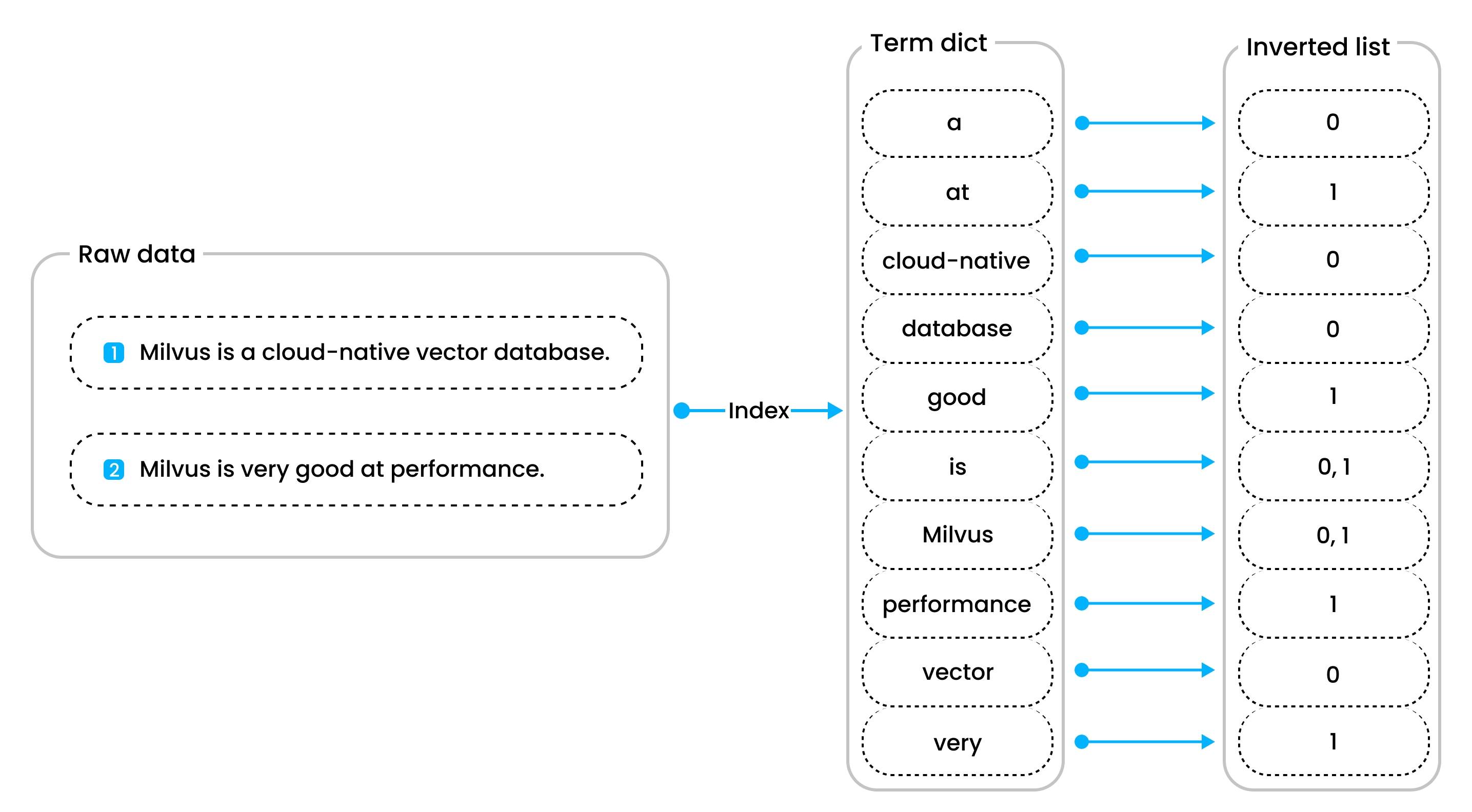
对于单点查询,当你查询包含“Milvus”的文档时,首先查询这个单词在词典的位置,然后查找对应的Inverted List中包含该单词的文档。